Asynchronous Programming is hard. Especially without the right tools. In one of my previous posts, I talked about how to make asynchronous programming more bearable using RxJS. Today we’re going to look at another implementation of the ReactiveX Api, RxSwift.
I’m not going to go into much detail on the basics of FRP, so if you don’t know what Reactive Programming is all about, I suggest you check out my previous posts or this great article about the fundamentals of RxSwift.
In its most basic way Functional Reactive Programming is about using event streams as your data and composing them via functions. In FRP, everything is a stream of events. We can then observe these streams and react accordingly. Swift already has a feature called Property Observers which go in a similar direction, but are much less powerful than RxSwift.
The actual term “Functional Reactive Programming” was originally coined in the 90s and it’s disputed whether the ReactiveX Api’s really are formulations of FRP. But I personally like to think of FRP as a programming style streching across different formulations (Elm creator Evan Czaplicki made a great video about this).
RxCocoa
RxCocoa is to Cocoa what RxSwift is to Swift. RxSwift provides the fundamentals of Observables and RxCocoa provides extensions to the Cocoa and Cocoa Touch frameworks to take advantage of RxSwift.
Now without further ado, let’s start building our first iOS application utlizing our reactive approach. For that you’ll need to install RxSwift and RxCocoa, so add them to your Pod- or Cartfile, depending on which you use.
Once that’s done we can begin for real. We’re going to create an application where we can save and review different movies on a scale from 0.0 to 10.0.
For starters, we’ll create a TableView and a corresponding TableViewCell in our Interface Builder. In our cell, we’d like to display the Title and the score, so we’ll add to UILabels to it. Then let’s also add an “Add” Button in our Navigation Bar, to dynamically add new Movies to our Table.
So far so good, next we’ll start writing some code for our model and our Cell. Our model is very simple right now and should only contain data for our title and our rating. Here’s how it should look:
class Movie {
let title: Variable<String>
let rating: Variable<Float>
init(){
title = Variable("")
rating = Variable(Float(5.0))
}
init(title: Variable<String>, rating: Variable<Float>){
self.title = title
self.rating = rating
}
}Notice, we define our title and rating as type Variable. If you know other flavors of Rx you can think of them as BehaviourSubjects.
Basically it emits the most recent item it has observed immediatly to each subscriber.
This allows us to push data to a Variable, but also allow subscribing to it, this will be useful later on.
Next up is our movie table cell:
class MovieTableViewCell: UITableViewCell {
@IBOutlet weak var ratingLabel: UILabel!
@IBOutlet weak var titleLabel: UILabel!
var movie: Movie?
}Really nothing special going on here at all. We’ve connected our two Labels to our Class via the @IBOutlet Annotation.
Now it’s time for the real meat of the application, our TableView. Because it’s quite a lot to handle, I’ve segmented the code into several smaller pieces:
class MovieTableController: UIViewController {
@IBOutlet weak var movieTable: UITableView!
@IBOutlet weak var addButton: UIBarButtonItem!
let disposeBag = DisposeBag()
let initialMovies: [Movie] = [
Movie(title: Variable("Die Hard"), rating: Variable(Float(10.0))),
Movie(title: Variable("Twilight"), rating: Variable(Float(1.0)))
]
func initState(addButton: UIBarButtonItem) -> Observable<[Movie]> {
let add = addButton.rx_tap
.map{_ in Movie()}
.scan(initialMovies, accumulator: { (acc,cur) in
var copy = acc
copy.append(cur)
return copy
})
return add.startWith(initialMovies)
}
func setupCell(row: Int, element: Movie, cell: MovieTableViewCell){
cell.movie = element
element.title.asObservable()
.bindTo(cell.titleLabel.rx_text)
.addDisposableTo(self.disposeBag)
element.rating.asObservable()
.map{String($0)}
.bindTo(cell.ratingLabel.rx_text)
.addDisposableTo(self.disposeBag)
}
Now this certainly looks like a lot, but it’s actually kind of simple. At first we set up our DisposeBag.
This is needed, because the Swift runtime doesn’t have Garbage Collection, but relies on Automatic Reference Counting.
To avoid memory leaks, we’ll have to put our Subscriptions into a DisposeBag.
In our initState function we retrieve a Stream of button pressed from our addButton, map each press, to create a new Movie,
then use the scan operator to add the new movie to our array and finally tell it to start with our initial movies.
Sadly Swift doesn’t support immutable appends, so we have to do it the verbose way of copying, appending and returning the copy.
In our setupCell method we configure our two labels, by binding our Observables to the rx_text field of the labels.
In the case of the Rating we first have to transform our Float values to Strings.
Now for the next part:
override func viewDidLoad() {
super.viewDidLoad()
let movies = initState(addButton)
movies.bindTo(movieTable.rx_itemsWithCellIdentifier("movieCell", cellType: MovieTableViewCell.self)) (configureCell: setupCell)
.addDisposableTo(disposeBag)
}
}In this snippet, we bind the Observable of Movie-Arrays to our TableView using the rx_itemsWithCellIdentifer method.
This returns a partially applied function, where we can pass the setup code we defined earlier for each individual cell.
Now the basics of our app should run. However, we now always add an empty Movie which we can’t edit at all. That’s rather unfortunate so let’s change that by adding a detail view where we can edit and add new Movies.
For that let’s start by creating a ViewController in the Interface Builder with a TextField for our movie title, a Slider for our review score and a Label to display the score in text. Next we’ll define a segue from our TableController to our DetailController.
Then we’ll need to define when to actually perform the segue.
In our TableView add the following code to the end of viewDidLoad:
movies.skip(1).subscribeNext { arr in
self.performSegueWithIdentifier("editMovie", sender: self.movieTable.visibleCells.last)
}.addDisposableTo(disposeBag)
movieTable.rx_itemSelected.subscribeNext { index in
self.performSegueWithIdentifier("editMovie", sender: self.movieTable.cellForRowAtIndexPath(index))
}.addDisposableTo(disposeBag)
And then also add this method:
override func prepareForSegue(segue: UIStoryboardSegue, sender: AnyObject?) {
if let movieController = segue.destinationViewController as? MovieDetailController {
if let movieCell = sender as? MovieTableViewCell{
movieController.movie = movieCell.movie
}
}
}When performing side effects such as switching views, we need to manually subscribe to our Observables using subscribeNext.
We can do this everytime we add to our movies and when we select a specific movie using rx_itemSelected.
In our prepareForSegue method we pass the movie from our cell to our MovieDetailController, which we have yet to define so let’s start right now.
First we create a ViewController in the Interface Builder with a TextField for our movie title, a Slider for our review score and a Label to display the score in text.
Then we create a class for our new controller:
class MovieDetailController: UIViewController {
@IBOutlet weak var titleField: UITextField!
@IBOutlet weak var ratingSlider: UISlider!
@IBOutlet weak var ratingLabel: UILabel!
var movie: Movie?
let disposeBag = DisposeBag()
override func viewDidLoad() {
super.viewDidLoad()
//define our stuff here
}
}Pretty straightforward. Now let’s define the relationships of our components and our movie. I’m not going to post the full code here since it’s just more of the same and the article is already quite code heavy, but here’s an idea of what to expect:
let rating = ratingSlider.rx_value.map { round(10 * $0)/10}
rating
.bindTo(movie!.rating)
.addDisposableTo(disposeBag)
rating
.map{String($0)}
.bindTo(ratingLabel.rx_text)
.addDisposableTo(disposeBag)Now after getting up to this point, this shouldn’t look very alien to you anymore.
We use the round function to truncate to 1 digit of precision and then bind it to our Movie model and our label’s rx_text.
If you’ve done everything right your app should now look something like this:
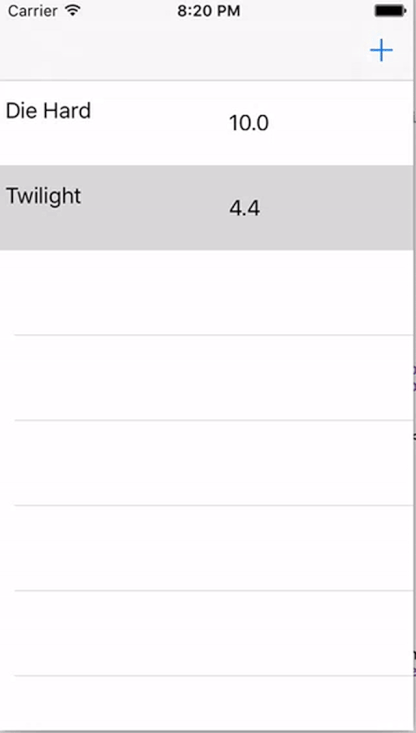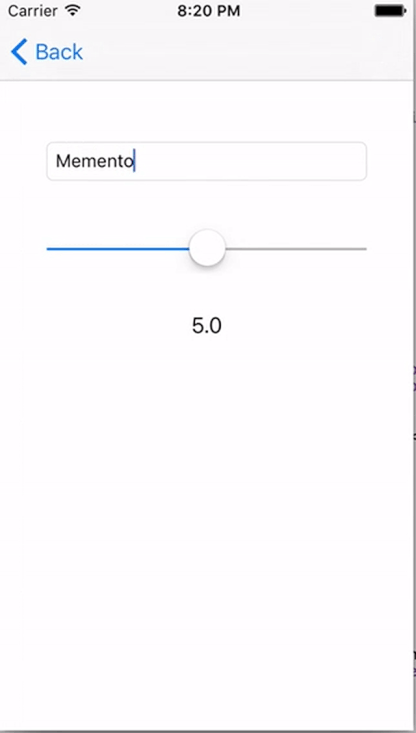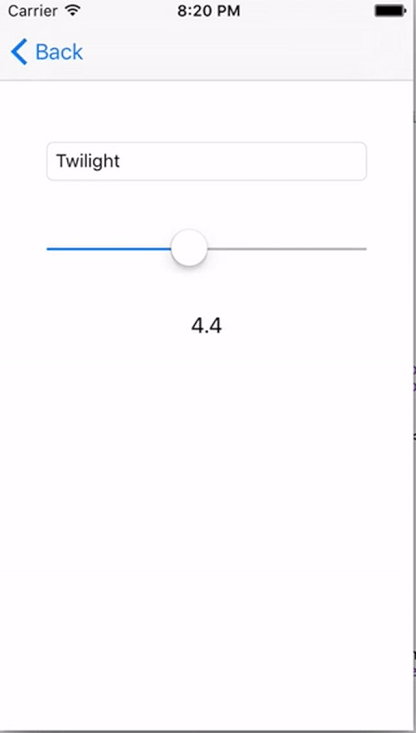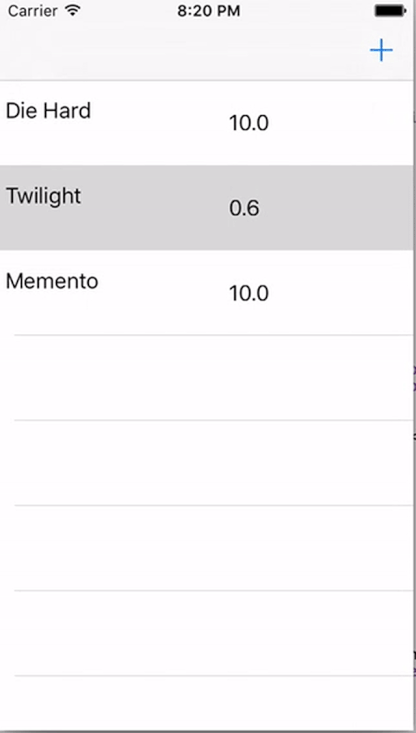
And with that we’re done a fully reactive approach to iOS programming. I hope you enjoyed this piece and try it out sometime. If you’re intrigued at all I suggest checking out the RxSwift Repo for more information. You don’t need to commit to it fully, but I feel RxSwift also works really well for just a couple of your Views.
As usual, all code shown here, can also be found in this GitHub repo