In my last post, I tried to show how to do Functional Reactive Programming in Angular 2. Now I’ve heard from some people that it’s too complicated and you shouldn’t ever really do it. I definitely understand that, switching programming paradigms is probably the most difficult change you can make, as it requires you to forget almost everything you already learned.
While showing the benefits of another programming paradigm is quite difficult and always to some extent subjective, showing some real performance benefits is a lot more objective. The real problem with mutable data, is that it can be slow while performing change detection.
Change detection
This problem, of course isn’t exclusive to Angular, but can be applied to e.g. React as well. There are some great resources out there to fully understand how Angular 2’s change detection system really works, but I’ll give it a shot and try to recap the most important points here.
The first problem really is how do you know a change occured?
When using mutable data, what you have to do is do a deep equality check, i.e. checking every single property of an object if it’s still the same.
If our component tree is very large, this can be very very expensive, because change detection will trigger on every browser event.
Starting to sound really ineffecient, right?
I did a quick diagram in draw.io to visualize what I’m saying:

When something changes (in red) all components have to be checked.
One solution to this problem would be to make our data immutable, preferably with some framework like Immutable.js.
With immutable data, we no longer have to do deep equality checks.
This is because the data can never be changed, so if we want to check for changes, we can just do a reference equality check.
So now instead of checking every single leaf of our tree, we just need to check the paths where our components aren’t referentially equal.
Here’s another diagram, to show you what’s changed:

This time we only have to check those that aren’t referentially equal and don’t have to check their children (in grey).
Also, if you want even more insight check out this video from React Conf about Immutable.js.
Moving on to Observables we can get even better performance!
This is because we can simply subscribe to our Observable to get notified when it emits an event immediatly.
We no longer have to go through all components from the root, but only the path from the root to our changed component.
This is how that looks:

So what does this mean in real terms?
In Angular 2 for normal use, we can guarantee that the change detection is O(n) where n is the number of components in the tree (which is already much faster than Angular 1 thanks to the Unidirectional data flow). When using Observables, we get essentially O(log(n)) which is awesome!
Now of course this still isn’t “real” data, so I took it upon myself to create a little “benchmark”.
I rewrote the app from the last article using ngModel and mutable data to see the differences.
So our new template now looks like this:
<div>
<h2>{{ form.name }}</h2>
<form>
<label>Name:</label>
<input type="text" [(ngModel)]="form.name"><br/>
<label>Height (cm):</label>
<input type="number" [(ngModel)]="form.height"><br/>
<label>Weight (kg):</label>
<input type="number" [(ngModel)]="form.weight"><br/>
</form>
<div><strong> Body Mass Index (BMI) = {{ getBmi() }}</strong></div>
<div><strong> Category: {{ getCategory() }}</strong></div>
</div>I ran both versions with lots and lots of these components and profiled them with Chrome. These are the results:
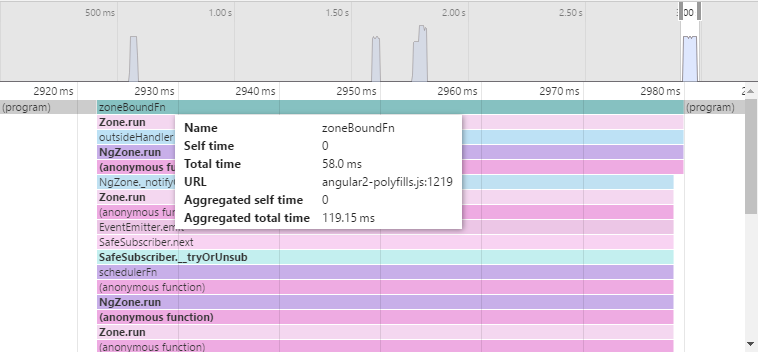
Here we’re using ngModel and we can see it takes about 58ms for one change detection cycle.
The total aggregated time of change detection throughout the period of testing is 119.15 ms.
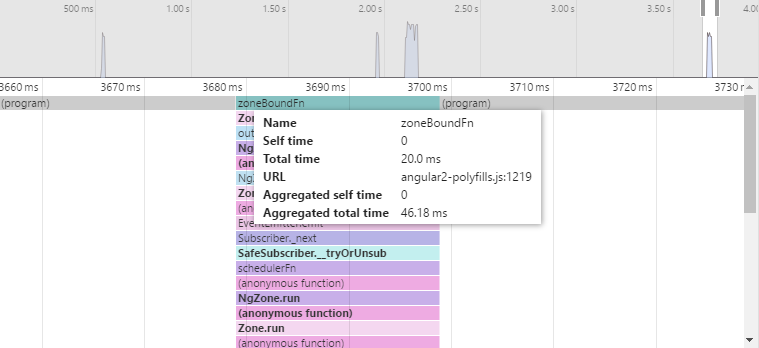
Here we’re using Observables and it’s already much quicker. We get 20 ms for this one function and an aggregated result of 46.18 ms. That’s about a 2.5-3x performance increase! Not bad if you ask me.
Conclusion
Of course, most of the time performance is not going to be that big of an issue, but if you have a complex app and you want it to also run on mobile, where cpu cycles are much more valuable, you might want to consider one of these approaches. You don’t even have to commit to one approach fully, but you can mix and match as you please. Check out Victor Savkin’s talk about change detection if you’d like to learn more. Another great resource, is this article by Pascal Precht, where he gives a complete breakdown about change detection in the more general sense. Hope you enjoyed reading this and would love to hear your thoughts!